Getting started
|
This documentation covers our Open Source solver to build a model from scratch. We also provide off-the-shelf models to solve common planning problems. These can be found here. |
Timefold Solver can be used in two ways. Pick the approach that best fits your architecture:
Deploy a fully isolated optimization service. This opinionated approach reduces the amount of boilerplate code needed to get to a running application. |
Add the solver as a dependency and wire it into your application however you like. Use Spring Boot, Quarkus… or no framework at all. |
| Run as a service | Embed as a library | |
|---|---|---|
Best for |
Running optimization as a standalone, isolated service that is easier to integrate, orchestrate & scale |
Embedding the solver into an existing application |
Ease of use |
Minimal setup: the framework handles REST endpoints and lifecycle for you |
Requires manual wiring: you manage configuration, lifecycle, and integration |
Integration |
Opinionated, ready-to-run service built on Quarkus |
You control how the solver is wired into your application. Integrations for Spring Boot and Quarkus available. |
Flexibility |
Constrained by design, the service only runs optimization |
Use any framework or no framework at all |
Status |
Stable |
Stable |
Run as a service
This is the approach we recommend for integrating Timefold Solver into a larger system, and it is the approach we use ourselves when building optimization models at Timefold.
The service has a single responsibility: running optimization. It receives a dataset, solves it, and returns the result over a well-defined REST API. That is all it does.
Why no database? Deliberately. The service does not store datasets, manage user state, or own any persistence layer. Your application already has a database; the service does not need one. This makes the service stateless, trivially scalable, and completely free of operational concerns like schema migrations or data ownership. When optimization is one step in a larger workflow, a stateless service with a clean API slots into any architecture without friction.
Why opinionated? An opinionated framework means less boilerplate, fewer ways to get it wrong, and a consistent shape that we all can reason about together. The library approach gives you full control; this approach gives you a proven path.
To get started, see Getting started: building a service.
Embed as a library
The library approach gives you the solver core as a dependency. You integrate it into your application however you see fit. There are no constraints on your application framework or architecture.
The following getting started guides demonstrate the library approach:
-
-
The minimal starting point. Build a plain Java or Kotlin application with no additional framework.
-
-
-
Build a REST application with Java or Kotlin on top of Quarkus, a popular Java platform that supports native compilation.
-
-
-
Build a REST application with Java or Kotlin on top of Spring Boot, a popular Java platform that supports native compilation.
-
All three guides optimize a school timetable for students and teachers:
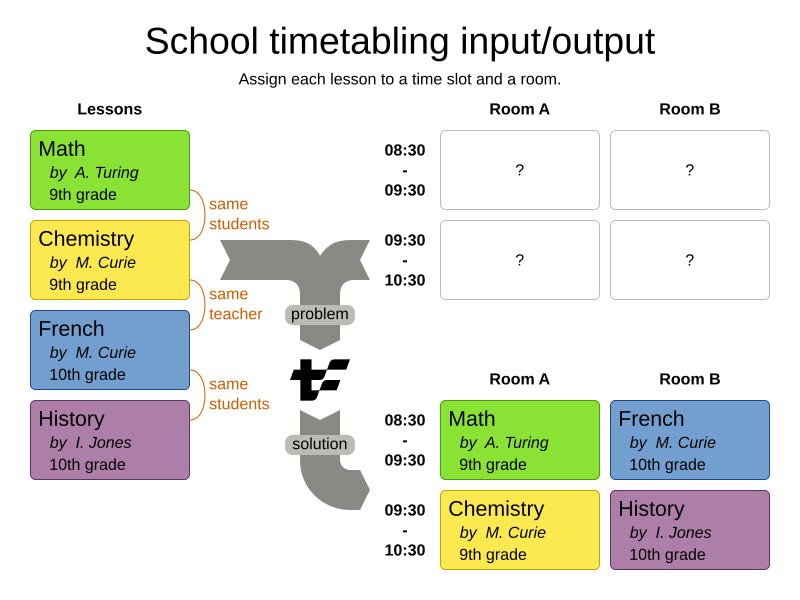
| The timefold-quickstarts repository contains the source code for all these guides. |
For additional use cases using the library approach,
take a look at the timefold-quickstarts GitHub repository.